Stay informed and never miss an Core update!
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.


Agentes de inteligencia artificial, una nueva revolución tecnológica que está cambiando el ecosistema del software, tal como lo conocíamos
INTRODUCCION:
Podemos decir, que el año 2025 en materia de tecnología, estuvo prácticamente centrado en un único tema: Inteligencia Artificial, y dentro de este, principalmente en agentes de inteligencia artificial (Agentic AI).
Más allá de la espiral publicitaria de los analistas y empresas del mercado, la realidad es que los agentes de inteligencia artificial son una disrupción tecnológica que está cambiando fuertemente las aplicaciones de negocio como las conocemos hoy, fundamentalmente porque esta nueva tecnología permite modernizar la manera de ejecutar la lógica de negocio de dichas aplicaciones haciéndolas más autónomas.
Este, es el primero de una serie de artículos sobre nuestra humilde experiencia relacionada al desarrollo de agentes de inteligencia artificial realizados durante el 2025 para pruebas de conceptos y soluciones reales de negocio construidas para clientes, basadas en distintos marcos de trabajo, tales como: Akka, Langchain y Microsoft Autogen.
Existen numerosos artículos que explican en profundidad qué es un agente de inteligencia artificial, los distintos frameworks y la manera en que resuelven distintos tipos de necesidades.
En esta serie de artículos, describiremos principalmente cuáles fueron los requerimientos de negocio, cómo resolvimos algunos de los desafíos que se nos presentaron con los patrones existentes, y algunas de las lecciones aprendidas.
En las dos primeras partes de esta serie, nos centraremos en una implementación con el framework AutoGen, principalmente para investigación y experimentación. En la tercera y cuarta partes, analizaremos aspectos a considerar en entornos reales y productivos, y mostraremos una experiencia con Akka. Finalmente, en la quinta parte, presentaremos una implementación con el framework Langchain. A continuación, la primera parte.
PARTE I:
Nuestro primer desafío fue una prueba de concepto para un cliente del sector público en Argentina que necesitaba optimizar mediante IA, su capacidad de atención a ciudadanos debido a un cambio legislativo a nivel nacional, que generó un fuerte incremento en la cantidad de reclamos relacionados a la titularidad del dominio en las operaciones de compra o transferencia de un automotor.
Básicamente, para esta entidad, la cantidad de trámites a atender pasaron de unos 3.000 al año a 1.500 diarios, esto es, un aumento de casi 200 veces. Y por este motivo, se solicitó automatizar mediante IA el flujo de trámite de “informe de dominio”.
Caso de Uso: Automatizar el procesamiento de trámites de “Informe de transferencia de dominio” para evitar la intervención humana en la lectura y análisis de títulos de automotor.
El desafío tenía los siguientes requerimientos:
Funcionales:
No Funcionales:
Según los requerimientos anteriores, para esta prueba de concepto elegimos el marco de trabajo de Microsoft AutoGen y los modelos de lenguajes (LLMs) de Ollama.
A continuación, listamos frameworks, librerías y lenguajes utilizados:
El primer enfoque fue diseñar un flujo de trabajo sencillo, de dos pasos secuenciales, ejecutados por agentes inteligentes: dos del tipo “asistente”, esto es, agentes que están preparados para resolver tareas usando LLMs, donde el primero, llamado OCR_agent, se encarga de extraer texto de los documentos de “Título del Automotor”.
Un segundo agente, llamado Formatter_agent, se encarga de generar los resultados de la extracción del primer agente en un formato de salida preestablecido.
El tercer agente del tipo “proxy de usuario” que llamamos User_proxy, y cuya función es permitir interactuar con un usuario, ejecutar código y proporcionar comentarios a los otros agentes.
Una característica específica de AutoGen, es que es un framework de conversación multiagente, esto es: utiliza agentes conversables, los cuales además de tener un rol específico, pueden chatear o pasar mensajes entre sí para iniciar o continuar una conversación.
Ahora bien, uno de los primeros desafíos con los que nos encontramos, fue poder leer e interpretar correctamente la información contenida en los documentos de “Título del Automotor” los cuales contienen datos relacionados a la titularidad y a la identificación del vehículo en un esquema clave-valor.
A continuación un ejemplo de un documento digital de Título del Automotor con ciertos textos ocultos por cuestiones de privacidad.
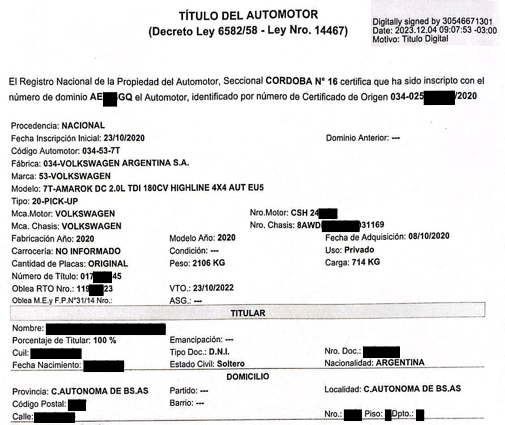
Como se puede observar, los pares de clave-valor se encuentran en distintas secciones y áreas del documento. Veremos que esto dificulta la tarea del lector OCR.
Para el agente OCR, que requiere leer archivos de imágenes y extraer datos del título del automotor, en una primera instancia, elegimos una librería llamada ollama.chat, pero dado que la misma no soportaba archivos PDF, elegimos otra librería de Ollama llamada OCRProcessor, un paquete python moderno que utiliza modelos de lenguaje de visión de última generación para extraer texto desde imágenes y archivos PDF.
Entre las ventajas de este paquete, podemos destacar, en primer lugar, que soporta como entrada varios modelos de visión o VLMs que son modelos del tipo multimodal que toman texto e imágenes o videos como entrada y producen texto como salida, generalmente en forma de descripciones de imágenes o videos, respondiendo a preguntas sobre su contenido. Estos modelos pueden ejecutarse de manera local. También soporta distintos formatos de salidas tales como: texto, markdown, JSON, clave-valor, etc.
Además, permite procesar múltiples archivos en un esquema de procesamiento por lotes (batch).
Y por último, permite modificar el prompt para dar instrucciones personalizadas de extracción de texto.
Para encapsular la funcionalidad de extracción como una herramienta, definimos una función llamada run_ocr que usa el paquete OCRProcessor y es invocada desde el agente inteligente OCR_agent. Recordemos que los agentes del tipo asistentes sólo interactúan con modelos LLMs y no pueden ejecutar código por sí mismos, por ello, esa tarea es delegada al agente User_proxy.
En resumen, el flujo de trabajo tiene la siguiente secuencia:
User_proxy -> OCR_agent -> User_proxy: run_ocr() -> OCR_agent -> Formatter_agent -> User_proxy
Otra consideración relevante es que podemos usar distintos modelos de lenguaje, según las funciones y agentes que intervienen. En este caso, usamos un modelo de visión o VLM “qwen2.5vl:7b” para extraer datos, y un modelo de texto o LLM: “llama3.2:3b” para interpretar las respuestas de cada agente.
En cuanto al prompt de este agente, dado que su función es extraer los datos tal cual los pueda reconocer, en el mismo, se refuerza el hecho de no cambiar nada ni inferir algo que no esté explícitamente en el documento.
Otro punto a destacar es que, aunque los textos a extraer están en idioma español, según las pruebas realizadas, descubrimos que si usábamos prompts en inglés la respuesta del agente era más rápida, por lo tanto, redactamos todos los prompts en inglés.
A continuación, la definición de la función con el uso del modelo de visión, y el prompt personalizado para extraer texto tal cual los reconoce.
def run_ocr(file_path: str) -> str:
ocr = OCRProcessor(model_name='qwen2.5vl:7b')
result = ocr.process_image(
image_path=file_path,
format_type="text",
custom_prompt=""" Extract all visible text from this image in Spanish **without any changes**.
- **Do not summarize, paraphrase, or infer missing text.**
- Retain all spacing, punctuation, and formatting exactly as in the image. - If the text is unclear or partially visible, extract as much as possible without guessing.
- **Include all text, even if it seems irrelevant or repeated.** """, # Optional custom prompt
language="Spanish"
)
return result
Luego, para ayudar a identificar los textos claves que nos interesa extraer como clave-valor, usamos como instrucciones un prompt específico para el agente ocr_agent:
OCR_tasks = [""" Extract text from file provided, and provide it in raw text format by invoking the 'run_ocr' tool.
- The value for the key 'Dominio' is located after the words 'número de dominio' in the paragraph that starts with 'El Registro Nacional de la Propiedad del Automotor'.
- The value for the key 'Nombre Titular' is located after the word 'Nombre:' from the section "TITULAR" only.
- The value for the key 'Cuil' is located after the word 'Cuil:' from the section "TITULAR".
- The value for the key 'Nro. Doc.:' is located after the word 'Nro. Doc.:" from the section "TITULAR" only.
- Extract the rest of the key-values you find in the text:""",
]
En cuanto al segundo agente Formatter_agent, su función es presentar los resultados obtenidos por el OCR_Agent en un formato de salida JSON según una estructura predefinida para que otro módulo o servicio externo lo pueda utilizar para completar el informe de dominio. Este agente, tiene como instrucciones el siguiente prompt:
Formatter_tasks = [""" You must format the text from the OCR text extraction to a JSON output.
- Format the response as JSON, **strictly preserving** the results from the extraction, do not change or guess any value.
- In the case one value is not readable or not present, put "" as value.
- Output your response in the following JSON format
{
"Dominio" : "value",
"Datos del vehículo" : {
"Fabrica": "value",
"Marca" : "value",
"Modelo" : "value",
"Nro motor" : "value",
"Nro chasis" : "value",
"Fabricación año" : "value",
"Fecha Incripcion inicial" : "value"
},
"Titular" : {
"Nombre" : "value",
"Porcentaje del Titular" : "value",
"Cuil" : "value",
"Tipo Doc." : "value",
"Nro. Doc." : "value",
"Fecha Nacimiento" : "value",
"Estado civil" : "value"
},
"Domicilio" : {
"calle" : "value",
"Nro." : "value",
"Piso" : "value",
"Dpto." : "value"
}
}
- Reply TERMINATE when the task is done.""",
]
Por último, para iniciar la secuencia del flujo de trabajo de los agentes, arrancamos la conversación o chat entre ellos de la siguiente manera:
chat_results = user_proxy.initiate_chats(
[
{
"recipient": ocr_agent,
"message": OCR_tasks[0],
"clear_history": True,
"silent": False,
"max_turns": 2,
"summary_method": "last_msg",
},
{
"recipient": formatter_agent,
"message": Formatter_tasks[0],
"silent": False,
},
]
)
Como puede observarse, para contener y evitar que los agentes conversen indefinidamente, limitamos el llamado al agente ocr_agent a dos (2) ejecuciones.
El código fuente completo (< 120 líneas) de estos agentes de IA se detalla a continuación:
import autogen
from autogen import register_function
from ollama_ocr import OCRProcessor
file_path = "./data/example.pdf"
# CONFIG_LIST file should be a JSON array of LLM configurations, for example:
#[{
# "model": "llama3.2:3b",
# "base_url": "http://localhost:11434/v1",
# "api_key": "ollama",
# "price": [0, 0]
#}]
config_list = autogen.config_list_from_json(env_or_file="CONFIG_LIST")
llm_config = {"config_list": config_list, "cache_seed": None,"temperature": 0.0,}
OCR_tasks = [""" Extract text from file provided, and provide it in raw text format by invoking the 'run_ocr' tool.
- The value for the key 'Dominio' is located after the words 'número de dominio' in the paragraph that starts with 'El Registro Nacional de la Propiedad del Automotor'.
- The value for the key 'Nombre Titular' is located after the word 'Nombre:' from the section "TITULAR" only.
- The value for the key 'Cuil' is located after the word 'Cuil:' from the section "TITULAR".
- The value for the key 'Nro. Doc.:' is located after the word 'Nro. Doc.:" from the section "TITULAR" only.
- Extract the rest of the key-values you find in the text:""",
]
Formatter_tasks = [""" You must format the text from the OCR text extraction to a JSON output.
- Format the response as JSON, **strictly preserving** the results from the extraction, do not change or guess any value.
- In the case one value is not readable or not present, put "" as value.
- Output your response in the following JSON format
{
"Dominio" : "value",
"Datos del vehículo" : {
"Fabrica": "value",
"Marca" : "value",
"Modelo" : "value",
"Nro motor" : "value",
"Nro chasis" : "value",
"Fabricación año" : "value",
"Fecha Inscripción inicial" : "value"
},
"Titular" : {
"Nombre" : "value",
"Porcentaje del Titular" : "value",
"Cuil" : "value",
"Tipo Doc." : "value",
"Nro. Doc." : "value",
"Fecha Nacimiento" : "value",
"Estado civil" : "value"
},
"Domicilio" : {
"calle" : "value",
"Nro." : "value",
"Piso" : "value",
"Dpto." : "value"
}
}
- Reply TERMINATE when the task is done.""",
]
def run_ocr(file_path: str) -> str:
ocr = OCRProcessor(model_name='qwen2.5vl:7b')
result = ocr.process_image(
image_path=file_path,
format_type="text",
custom_prompt= """ Extract all visible text from this image in Spanish **without any changes**.
- **Do not summarize, paraphrase, or infer missing text.**
- Retain all spacing, punctuation, and formatting exactly as in the image.
- If the text is unclear or partially visible, extract as much as possible without guessing.
- **Include all text, even if it seems irrelevant or repeated.** """, # Optional custom prompt
language="Spanish"
)
return result
ocr_agent = autogen.AssistantAgent(
name="OCR_agent",
llm_config=llm_config,
system_message=f"You are an Optical Character Recognition (OCR) assistant, extracts text from file '{file_path}', and provide it in raw text format.",
)
formatter_agent = autogen.AssistantAgent(
name="Formatter_agent",
llm_config=llm_config,
system_message="""You are an expert formatting text to a JSON output from the OCR text extraction
Reply "TERMINATE" at the end when everything is done.
""",
)
user_proxy = autogen.UserProxyAgent(
name="User_proxy",
human_input_mode="NEVER",
is_termination_msg=lambda x: x.get("content", "") and x.get("content", "").rstrip().endswith("TERMINATE"),
code_execution_config= False,
)
register_function(
run_ocr,
caller=ocr_agent,
executor=user_proxy,
name="run_ocr",
description="Extract all the text readable from image or pdf using ollama-ocr."
)
chat_results = user_proxy.initiate_chats(
[
{
"recipient": ocr_agent,
"message": OCR_tasks[0],
"clear_history": True,
"silent": False,
"max_turns": 2,
"summary_method": "last_msg",
},
{
"recipient": formatter_agent,
"message": Formatter_tasks[0],
"silent": False,
},
]
)
Código fuente: Agent01.py
Al final de la serie de artículos, compartimos el repositorio con los programas fuentes aquí mostrados.
Resultados:
Se realizaron diversas pruebas con distintos modelos de lenguaje de visión, tales como: llama3.2-vision:11b, qwen2.5vl:7b, granite3.2-vision, gemma3.4b, minicpm-v, y se ajustaron configuraciones como por ejemplo la temperatura. También se usaron varios documentos de Títulos de Automotor con distintos formatos de archivos (.pdf, .png, .jpg, .tiff, etc.).
Descubrimos que, efectivamente, algunos modelos son más efectivos y eficientes que otros, pero además, mientras los documentos eran archivos .pdf generados por el mismo organismo “Registro Nacional de Propiedad del Automotor”, o éstos eran imágenes del tipo .png o .jpg de buena calidad o resolución, esto es, superior a 100 (DPI) pixeles por pulgada, los resultados eran satisfactorios y cumplían con los requerimientos funcionales.
Sin embargo, cuando los archivos eran imágenes de baja resolución, descubrimos que el LLM alucinaba o inventaba valores que no se corresponden con los datos reales, y para peor, esto sucedía con mayor frecuencia cuando los datos a extraer eran numéricos, como por ejemplo el número de identificación del titular o CUIL, un dato clave para el correcto procesamiento de este tipo de gestión.
Esto causaba un serio problema de precisión en los resultados y limitaba el uso de esta solución.
Por tal motivo, continuamos iterando la solución, con nuevas estrategias de control y guiado de los agentes.
Estas estrategias y alternativas de solución se detallan en la Parte II de esta serie.
Créditos: Foto de portada de Igor Omilaev en Unsplash
